[ < ] [ globaleÜbersicht] [ Kapitelübersicht ] [Stichwortsuche] [ > ]
Das größte Potential um die Rechnerleistung zu steigern, liegt in fortschrittlicheren Rechnerarchitekturen. So werden Mikroprozessoren zum Beispiel in Generationen eingeteilt :
Instruktionen werden einzeln abgearbeitet typischer Vertreter: INTEL 8080
(ab 1979): Einfache Pipelines werden eingeführt. typischer Vertreter: MOTOROLA 68000
(ca. 1984): On-Chip Cache wird eingeführt, fünfstufige Pipline. typischer Vertreter: MOTOROLA 68020
(ca. 1989): Die Superskalartechnik wird eingeführt. typischer Vertreter: INTEL 960
5.Generation (Heute): Die Out-of-Order Execution wird eingeführt. typischer Vertreter: P6
Daneben unterscheidet man noch folgende Entwicklungen in den letzten Jahrzehnten:
Vektorrechner (siebziger Jahre) Reduced Instruction Set Computer - RISC (1981-1983) verbreiteter Einsatz von Parallelrechnersystemen (neunziger Jahre)
Es gibt zwei Möglichkeiten um die Leistung eines Prozessors zu steigern : Erhöhen der Taktfrequenz Den CPI-Wert möglichst gering zu machen.
Ad 1. Dem Erhöhen der Taktfrequenz sind (physikalische) Grenzen gesetzt. VLSI (Very Large Scale Integration).
Grenzen: Eine zur Zeit unüberbrückbare Barriere ist die Lichtgeschwindigkeit (ca 300.000 km/s). Außerdem spielen kommerzielle Überlegungen eine Rolle. Zu hohe Forschungs- und Entwicklungskosten bei ständig steigender Konkurrenz.
Ad 2. Sind alle technischen Möglichkeiten die Prozessorleistung zu erhöhen ausgeschöpft, besteht die Möglichkeit durch Parallelismus den CPI-Wert unter 1 zu drücken. Es müssen also mehr als nur eine Instruktion zugleich ausgeführt werden. In die Kategorie Leistungssteigerung durch Parallelismus fallen: das Pipeline-Prinzip das Superskalar-Prinzip und die Vektorverarbeitung.
Pipelining: Die Befehle werden zerlegt und ähnlich einem Fließband abgearbeitet. Probleme treten dabei auf, wenn eine Abhängigkeit zwischen aufeinanderfolgenden Befehlen besteht, oder wenn bedingt Sprünge auftreten. Es ist entweder Aufgabe der Architektur oder des Compilers, diese Probleme zu minimieren.
Superpipelines RISC "underpipelined" - Prozessoren.
Superskalare Architekturen: Zwei oder mehrere Befehle werden exakt zur gleichen Zeit ausgeführt. Dazu muß aber die nötige Hardware vorhanden sein. Dabei ist wieder die Abhängigkeit aufeinanderfolgender Befehle zu berücksichtigen.
Superskalar Prozessoren (dynamisch) VLIW Prozessoren (statisch) Vektorprozessoren: Viele mathematische Probleme lassen sich in Form von Vektoroperationen ausdrücken. Vektorprozessoren berücksichtigen dies durch spezielle Hardware (z.B.: Vektorregister). Ein Geschwindigkeitszuwachs wird auch durch den Einsatz des Superskalar-Prinzips erreicht.
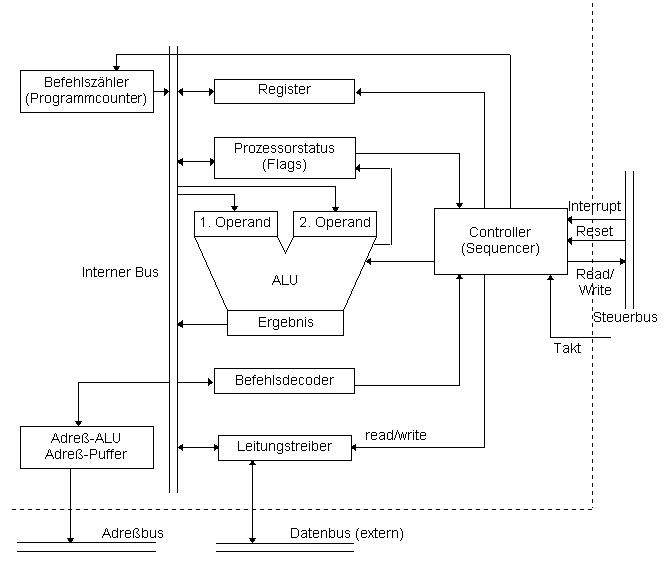
Der hier beschriebene Mikroprozessor ist nur ein hypothetisches Modell, da sich die einzelnen Mikroprozessoren, je nach Bauweise und Generation, im Detail stark unterscheiden. Die gezeigten Einheiten stellen nur die wichtigsten Funktionsteile dar, die alle Prozessoren gemeinsam haben:
Die wichtigsten Bestandteile eines Prozessors - die Zentraleinheit - sind die Steuereinheit (Controller), die Recheneinheit (ALU) und die Register.
Sie reguliert die Reihenfolge, in der die Befehle aus dem Arbeitsspeicher gelesen werden. Weiters überwacht sie die Verbindungen zu den Peripheriegeräten (Bildschirm, Drucker, ...) über den Leitungstreiber und steuert den Registersatz und die Recheneinheit.
Die ALU führt sowohl mathematische und arithmetische Operationen als auch logische Verknüpfungen durch.
Der Registersatz wird, im Unterschied zum Arbeitsspeicher, nicht über Adressen sondern direkt über einen Befehlscode angesprochen. Er besteht aus Mehrzweckregister, die für die Bearbeitung von Zwischenwerten zur Verfügung stehen, Statusregister, die den aktuellen Zustand des Computers mit Hilfe von Flags angeben und Segmentregister, die dem Prozessor helfen, sich im Arbeitsspeicher zurechtzufinden. Die Anzahl dieser Teilregister ist je nach Prozessorbauweise unterschiedlich.
Der Befehlscode decodiert die im Microcode gespeicherten Befehle und leitet sie an die Steuereinheit weiter.
Die AU berechnet die benötigten Adressen in der Adreß-ALU und speichert sie vorübergehend im Adreß-Puffer. Von dort können sie von der Steuereinheit bei Bedarf entnommen werden.
Der interne Bus stellt die Verbindungen zwischen den einzelnen Funktionseinheiten dar. Über den Daten-, Adreß- und Steuerbus gibt es auch Verbindungen nach außen:
Über ihn findet der Datentransfer statt. Seine Breite ist ein Merkmal für die Leistungsfähigkeit des Prozessors.
Er stellt die Verbindung zu den einzelnen Speicherstellen des Hauptspeichers dar. Dieser besteht aus Festwertspeicher (ROM) und flüchtigem Speicher (RAM), auch Arbeitsspeicher genannt. Der im ROM (Read Only Memory) gespeicherte Inhalt kann nicht verändert werden und bleibt beim Wegfallen der Betriebsspannung erhalten. Der Inhalt eines RAMs (Random Access Memory) kann zwar beliebig verändert werden, beim Abschalten des Computers wird er aber gelöscht.
Er steuert den Übertrag der Signale in der Zentraleinheit (CPU) zur Steuerung aller Operationen.
Jedes Programm, selbst wenn es kein spezielles Mathematikprogramm ist, verwendet heutzutage (für einen �gewöhnlichen� Prozessor) komplizierte mathematische Operationen (z.B. bei graphischen Operationen, Fontgeneration, usw.). Um dem Prozessor zu entlasten und von diesen langwierigen Berechnungen (z.B. trigonometrische Funktionen, Exponentialfunktionen u.ä.) zu befreien, finden mathematische Koprozessoren (*) Verwendung. Ihr Befehlssatz ist speziell auf diese Aufgaben abgestimmt. Wenn der Hauptprozessor nun auf so eine Operation trifft, schickt er sie an den Koprozessor weiter. Während dieser an der Lösung des Problems arbeitet, kann der Hauptprozessor sich anderen Aufgaben (Tasks) widmen. Der Koprozessor meldet dem Hauptprozessor dann die Beendigung der Operation und dieser kann mit der Ausführung des Programms fortsetzen. Dadurch werden erhebliche Geschwindigkeitszuwächse erreicht. Besonders die Fließkommaverarbeitung wird von Koprozessor beschleunigt.
Ein sehr bekanntes Beispiel ist der INTEL i8087. Bereits 1976 entstanden bei INTEL konkrete Pläne für die Herstellung eines mathematischen Koprozessors. Aber erst 1980 wurde der 8087er als Koprozessor für den IBM PC veröffentlicht.
Viele Algorithmen , speziell in Anwendungen die sich mit Problemen der numerischen lineare Algebra befassen, lassen sich durch Vektoroperationen implementieren. Daher ist es naheliegend speziell abgestimmte Hardware herzustellen um die Rechenzeit zu verkürzen. Es werden also in Prozessoren, die für die numerische Datenverarbeitung hergestellt werden, Vektoroperationenin den Befehlssatz aufgenommen. Die Daten werden in spezielle Vektorregister geladen und von Vektoreinheiten verarbeitet. Durch starke Überlappungen bei der Ausführung dieser Operationen kommt es zu großen Geschwindigkeitsgewinnen. Da eine einzige Vektorrechnung vielen einzelne Operationen entspricht wird die Anzahl der auszuführenden Instruktionen reduziert und das Speichersystem wird entlastet. Ebenfalls positiv wirkt sich aus, daß die Komponenten eines Vektors normalerweise auch (physisch) hintereinander im Speicher abgelegt sind. Diese "örtliche Lokalität" der Daten kann durch eine starke Speicherverschränkung ausgenutzt werden. Außerdem fallen alle Verzögerungen weg, die entstehen, wenn man solche Vektoroperationen auf einem "gewöhnlichen" Prozessor simulieren muß (z.B. durch Schleifen). Das Superskalarprinzip ist natürlich auch auf Vektorrechnern übertragbar.
Pentium und PowerPC haben beide Ihre Vorteile. Sie unterscheiden sich in erster Linie durch die Art des Befehlssatzes, man unterscheidet zwischen RISC und CISC, oder auch zwischen Reduced oder Complex. Ein wesentlicher unterschied ergibt sich dabei aus der komplexen Adreßbildung des PowerPC und der sich daraus ergebenden Vorteile der RISC-Architektur dies nicht zuletzt aufgrund verschiedener Cache-Strategien.
Der Intel Pentium ist der zur Zeit wohl erfolgreichste und am weitesten verbreitete Mikroprozessor im PC-Bereich. Die wichtigsten Vertreter seiner Klasse sind die 100, 133, 166 und 200 MHz Varianten der einzelnen Hersteller. Der Prozessor arbeitet mit einer 3.3 Volt Spannung. Die Varianten bis 120 MHz sind mit der 0.6 m BiCMOS Technologie ausgeführt, die Varianten mit darüberliegenden Taktfrequenzen wurden bereits mit der 0.35 m BiCMOS Technologie gebaut (den 120MHz Pentium gibt es in beiden Versionen). Zu Beginn zeichnete sich der Intel Pentium vor allem durch zahlreiche mehr oder weniger schwere Fehler aus. Es befinden sich ca. 3.3 Millionen Transistoren auf einem Chip. Der externe Bustakt liegt zwischen 50 (75 MHz Variante) und 66 MHz (100,133,166,200 MHz Varianten). Seine eher bescheidenen Benchmarkwerte (SPECint_base95 : 4.14, SPECfp_base95 : 2.48 für die 133 MHz Version) zeigen aber bereits sein eher auf Ganzzahlverarbeitung eingeschränktes Tätigkeitsfeld. Doch wie überall in der EDV wird wohl auch der Pentium wohl bald Geschichte sein.
Sein Nachfolger ist der Intel Pentium Pro (150, 166, 180, 200 Mhz) in seinen verschiedenen Varianten. Verbessert hat sich hier vor allem die Ganzzahl - Verarbeitung (SPECint_base95 : 8.09, SPECfp_base95 : 5.99 für die 200 MHz Version) mit der neuen Virtuellen Systemarchitektur. Auch hier ist die 1st Level Cache Größe 8+8 KByte. Der 2nd Level Cache liegt zwischen 256 und 512 KByte, wobei sich die Modelle der einzelnen Hersteller und deren Funktionen zum Teil wesentlich unterscheiden. Auch die zunehmende Entwicklung in Richtung Multimedia wird bei der Entwicklung der Prozessoren bereits berücksichtigt.
[http://www.maths.lth.se/bengtl/horna/spectable.html]
Der Cyrix 6x86 ist das Konkurrenzprodukt zum Pentium. Es gibt ihn in fünf Klassen : P200+, P166+, P150+, P133+ und P120+ (wobei diese p X + - Wertung bedeutet, daß der jeweilige Prozessor schneller ist als der Pentium mit der Taktfrequenz X). Der 6x86 gehört zu den superpipelined und superskalar Prozessoren. Er ist mit 2 integer und einer 80 bit floating point Unit ausgerüstet und benutzt die gängigen "Architekturtricks" wie Register renaming, Out-of-Order-Completion, Branch prediction und spekulative Ausführung. Er verfügt über einen 16 KByte großen unified onchip Cache. Sein Nachfolger ist der voll MMX (Multi Media Extension) fähige M2.
Der AMD-X5 - 133 mit 133 MHz verfügt über 16 KByte unified onchip Cache. Eine sogenannte MMU (Memory Management Unit) organisiert die Speicheroperationen des Prozessors. Er wird ebenfalls in der 0.35-m CMOS-Technologie hergestellt.
Der Alpha 21164 mit einer Taktfrequenz von 333 MHz (es gibt auch 250, 266, 300, 350 oder 400 MHz Varianten !) verfügt über einen 1st Level Cache von 8+8 KByte (8 KByte Instruction- und 8 KByte Datacache) und 96 KByte onchip 2nd Level Cache. Er befindet sich mit seinen Benchmarkwerten (SPECint95 : 9.78, SPECfp95 : 13.4 - Peak-Werte für die 333 MHz Variante) im absoluten Spitzenfeld. Der Prozessor unterstützt maximal 1GByte Hauptspeicher. Daneben gibt es noch die "kleineren" Varianten : A21064, A21064A und A21066.
Dank Digital FX!32 laufen nun auch 32bit x86 Programme (Windows, Windows NT) auf Alpha Systemen, was deren Marktchancen erheblich steigert (Dataquest schätzt, daß der Windows NT Markt bis zum Jahr 2000 auf 50 Mio. Einheiten anwachsen wird! )
Der R4000 und sein direkter Nachfolger der R4400 ("echte" 64 Bit Prozessoren) von MIPS Technologies verfügt über eine pipelined FPU (Floating Point Unit) die 3 bzw. 4 Takte für eine single- bzw double precision Multiplikation benötigt. Diese Fließkommaeinheit arbeitet als Koprozessor für die CPU. Eine MMU (Memory Managing Unit) sorgt für eine schnelle Übersetzung der virtuellen Adressen. Getrennte Instruction- und Data- 1st Level Caches (jeweils 16 KByte) die beide direct mapped organisiert sind beschleunigen aufeinanderfolgende Speicherzugriffe auf die gleichen Daten. Die Integer Unit des R4400 besteht aus 8 Stufen, womit er zu den super-pipelined Prozessoren zählt.
Beim R10000 handelt es sich um einen Superskalarprozessor (bis zu vier Instruktionen pro Taktzyklus) der über getrenne Instruction- und Data- 1st Level Caches (jeweils 32 KByte) verfügt. Zusätzlich beschleunigt ein TLB (Translation Lookaside Buffer) mit 64 Einträgen die Speicherzugriffe. Es werden Architekturtricks wie Register Renaming, Branch Prediction oder Out-Of-Order-Execution verwendet um die Pipeline möglichst gut auszulasten. Seine Benchmarkwerte (SPECint95 : 8.9, SPECfp95 : 12.5, Peak - Werte für die 200 MHz Version!) eröffnen ihm ein breites Anwendungsfeld im Workstationbereich, so wird er z.B. im Indy Nachfolger O2 (beide von SGI - Silicon Graphics Inc.) eingesetzt.
[http://www.hp.com]
[http://www.mips.com]
Wurde von Motorolla so getauft weil er aus ca. 68000 Transistoren besteht und ist vor allem von historischem Interesse.
Der PA7200 wird mit Taktfrequenzen von 100 bis 200 MHz (256 KByte I-Cache / 256 KByte D-Cache) hergestellt und verwaltet maximal 1GByte Hauptspeicher. Benchmarkwerte (SPECint95 : 4.37, SPECfp95 : 7.54, Peak - Werte für die 200 MHz Variante !)
[http://www.alphastation.digital.com/products/a600.html]
Der PA8000 mit 180 MHz ist ein "echter" 64 Bit Prozessor dessen Besonderheit das Fehlen eines onchip Cache ist. Statt dessen arbeitet er mit einem externen Cache, der über einen speziellen Cache-Bus angekoppelt ist. Der PA8000 (PA steht übrigens für Precision Architecture) verfügt über vier Floating Point Units (2 für Multiplizieren/Addieren, 2 für Dividieren und Wurzelziehen) und 4 Integer Units (64 Bit breit). Damit ist er voll superskalarfähig. Die Multiplizier/Addier-Units sind pipelined (3 Takte Durchlaufzeit (Latency)), die Division/Wurzel - Units haben eine Durchlaufzeit von 31 Takten (bei Double Precision). Um Abhängigkeiten zwischen Befehlen aufzulösen benutz der Prozessor Register Renaming, Out-of-Order-Execution, spekulative Ausführung und so weiter. Ein Instruction Reorder Buffer mit 56 Einträgen bringt die Load/Store Operationen wieder in die richtige Reihenfolge. Weiters gibt es einen Branch-History-Table (256 Einträge) und einen Branch Target Address Cache (32 Einträge).
Benchmarkwerte (SPECint95 : 11.8, SPECfp95 : 20.2, Peak - Werte !)
PA8000 von HP
[http://www.hp.com]
[c't 8/96, Seite 23]
Der IBM Power2 mit 67 MHz (es gibt Varianten von 39 bis 135 MHz) ist mit 32 KByte I-Cache und 128 KByte D-Cache ausgerüstet. Der Prozessor, der max. 512 MByte Hauptspeicher verwalten kann, weist Spitzenwerte bei der Fließkommaverarbeitung auf : Benchmarkwerte (SPECint95 : 3.42, SPECfp95 : 10.23, Peak - Werte für die 67 MHz Variante!)
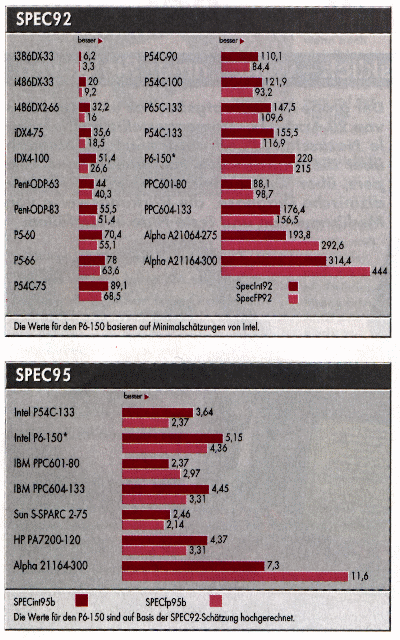
| Prozessor | Prozessor | Geschwindigkeit | SPECint95 | SPECfp95 | SPECint95b | SPECfp95b | SPECint92 | SPECfp92 |
| Intel | i8086 und i8087 | |||||||
| Intel | i80186 | |||||||
| Intel | i80286 | |||||||
| Intel | i80386 DX | 33 MHz | 6,2 | 3,3 | ||||
| Intel | i80486 DX | 33 MHz | 20 | 9,2 | ||||
| Intel | i80486 DX-2 | 66 MHz | 32,2 | 16 | ||||
| Intel | i80486 DX-4 | 75 MHz | 35,6 | 18,5 | ||||
| Intel | i80486 DX-4 | 100 MHz | 51,4 | 26,6 | ||||
| Intel | Pentium Overdrive ODP | 63 MHz | 44 | 40,3 | ||||
| Intel | Pentium Overdrive ODP | 83 MHz | 55,5 | 51,4 | ||||
| Intel | Pentium P5 | 60 MHz | 70,4 | 55,1 | ||||
| Intel | Pentium P5 | 66 MHz | 78 | 63,6 | ||||
| Intel | Pentium P54C | 75 MHz | 89,1 | 68,5 | ||||
| Intel | Pentium P54C | 90 MHz | 110,1 | 84,4 | ||||
| Intel | Pentium P54C | 100 MHz | 121,9 | 93,2 | ||||
| Intel | Pentium P54C | 133 MHz | 4.14 | 2.48 | 3.64 | 2.37 | 155,5 | 116,9 |
| Intel | Pentium P65C | 133 MHz | 147,5 | 109,6 | ||||
| Intel | PentiumPro P6 | 150 MHz | 5.15 | 4.36 | 220 | 215 | ||
| Intel | PentiumPro P6 | 200 MHz | 8.09 | 5.99 | ||||
| Intel | i860 | |||||||
| Cyrix | 6x86 | |||||||
| AMD | X5 | |||||||
| Alpha A21064 | 275 MHz | 193,8 | 292,6 | |||||
| Alpha A21164 | 300 MHz | 7,3 | 11,6 | 314,4 | 444 | |||
| Alpha A21164 | 333 MHz | 9.78 | 13.4 | |||||
| IBM, Apple, Motorola | PowerPC PPC601 | 80 MHz | 2,37 | 2,97 | 88,1 | 98,7 | ||
| IBM, Apple, Motorola | PowerPC PPC604 | 133 MHz | 4,45 | 3,31 | 176,4 | 156,6 | ||
| IBM | Power 2 | 67 MHz | 3,42 | 10,23 | ||||
| SGI | MIPS R4000 | |||||||
| SGI | MIPS R4400 | |||||||
| SGI | MIPS R6000 | |||||||
| SGI | MIPS R10000 | 200 MHz | 8.9 | 12.5 | ||||
| Motorola | 68000 | |||||||
| HP | PA7200 | 120 MHz | 4,37 | 3,31 | ||||
| HP | PA7200 | 200 MHz | 4.37 | 7.54 | ||||
| HP | PA8000 | 180 MHz | 11.8 | 20.2 | ||||
| Sun | S-SPARC 2 | 75 MHz | 2,46 | 2,14 |
Testen Sie sich selbst. Ausfüllen des Fragebogens .
[ < ] [ globaleÜbersicht] [ Kapitelübersicht ] [Stichwortsuche] [ > ]
{kind=link}